
티스토리 뷰
주식으로 1억을 만드는 방법은 2억으로 시작하는 거라는 말이 있습니다.

그만큼 투자라는 게 마냥 쉽고 달콤하지만은 않다는 것일텐데요.
주변에서 '카더라' 라는 말만 듣고, 또는 인터넷 방송 등에서 콕 찝어주는 종목만 아무것도 모른 채 매수를 하기보다는 최소한의 정보를 가지고 나름의 분석을 통해 거래를 하는 것이 반드시 필요하다고 봅니다.
(물론 그런다고 해서 수익이 발생한다는 보장은 절대 못합니다 ㅠㅠ)


아마 많은 분들이 N 사의 금융 페이지에서 주식 정보를 얻으실 텐데요.

저는 사실 주식 바보라서 어떻게 투자하시라고 말씀은 드리지 못하지만, 그나마 코스피 상위 종목의 우량주들 중에서 몇 개 종목을 선택하는게 들쑬날쑥한 동전주들보다는 안전하지 않을까 생각합니다.

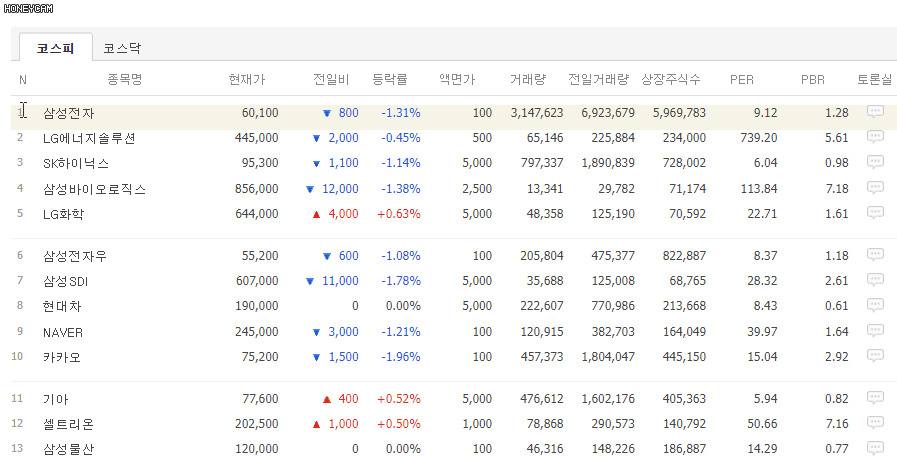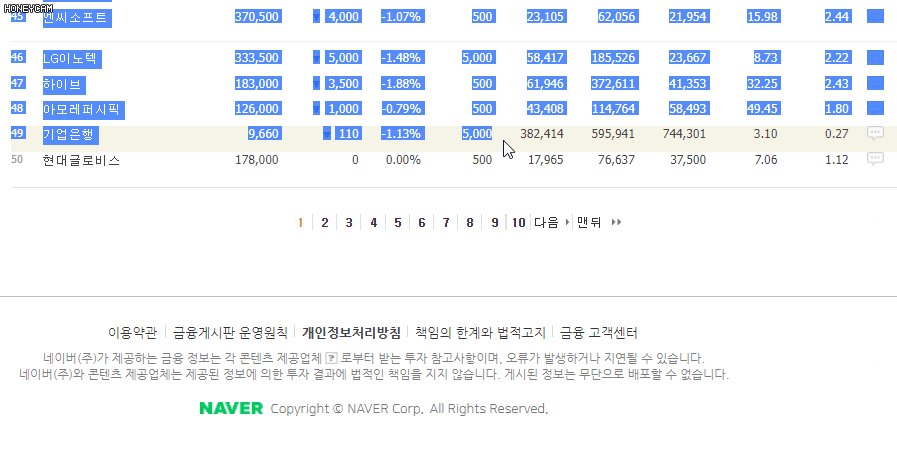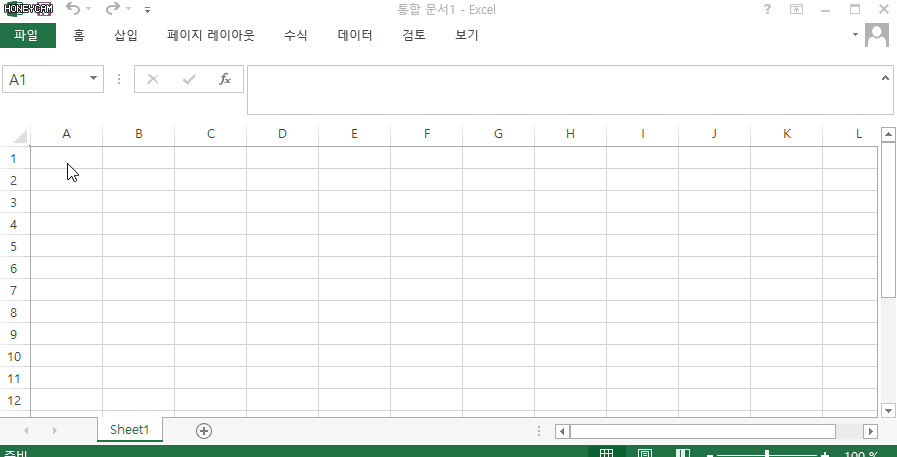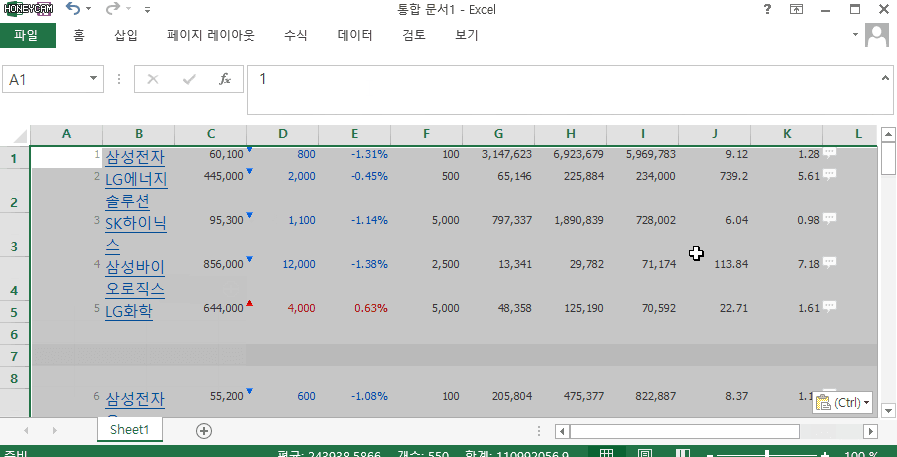
페이지 좌측의 시가총액 메뉴를 이용하면 대한민국 코스피 / 코스닥 종목들에 대해 시가총액 순으로 정렬을 시키고, 또 원하는 항목만 골라서 볼 수도 있는데요.

가령 '거래량, 전일거래량, PER, PRB, 외국인비율' 을 종목 선택 기준에 있어 중요하게 여긴다면 그 항목들만 선택하고 적용하기를 누르면 이렇게 화면이 바뀌게 됩니다.

그리고 페이지별로 총 50개씩의 종목들을 보여주는데요. 아쉽게도 네이버에서는 엑셀 다운로드 기능은 제공해주지 않네요. 다행히 복사는 막아놓지 않아서 수동으로 이 데이터들을 드래그 해서 엑셀 파일로 복붙을 하게 되면 표 형태로 만들어볼 수는 있습니다.
확인해보니 코스피 종목은 총 37페이지까지 존재하네요?
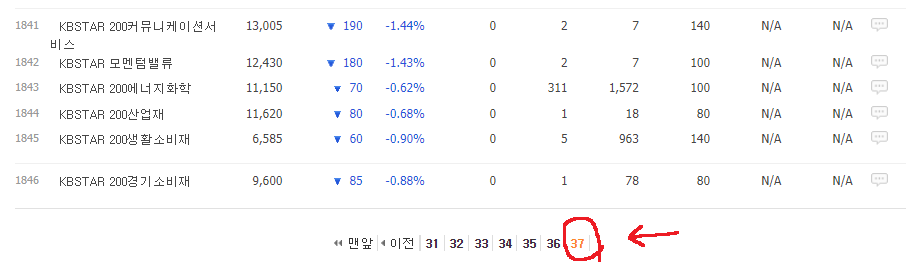
만약 이 모든 데이터를 엑셀로 가져와서 저장하고 싶다면 어떻게 해야 할까요?
그렇습니다. 마우스 드래그, 복사, 엑셀에 붙여넣기, 페이지 이동 <- 이 작업을 37번 하면 됩니다.

그런데 하루 지나서 다음날에 변경된 데이터를 다시 가져오고 싶다면?
위 작업을 또다시 37번 반복하면 됩니다.
내일도 37번,
모레도 37번,
다음주에도 또 반복,

힘들겠죠?
매일 37번씩 동일한 작업을 반복하는 건 정말 짜증나고 지치는 일일겁니다.
그래서 파이썬이 있지요!
파이썬을 이용하면 웹페이지에서 내가 원하는 데이터를 아주 쉽게 긁어올 수 있어요. 웹페이지의 성격에 따라 접근 방법이 조금 다를 수는 있는데, 이렇게 사용자가 옵션을 선택하는 동작, 즉 글자를 입력하거나 버튼을 클릭하거나 하는 등의 동작이 필요하다면 웬만하면 selenium 이라는 패키지로 해결됩니다. 아주 강력한 도구에요.
동작 없이 페이지 접속해서 바로 데이터를 가져와도 된다고 하면 requests 도 좋은 선택입니다.
여기에서는 selenium 을 이용해볼게요.
참고로 selenium 을 쓰기 위해서는 브라우저를 제어하기 위한 WebDriver 라는 것이 필요합니다. 크롬을 이용한다면 chromedriver.exe 란 파일을 받으면 되는데, 구글에서 chromedriver 로 검색하면 바로 다운로드 받으실 수 있어요. 주의할 점은 사용중인 크롬의 버전과 일치하는 파일을 받으셔야 한다는 겁니다. 그렇지 않으면 동작이 안돼요. chromedriver 는 파이썬 코드와 동일한 위치에 두면 됩니다.
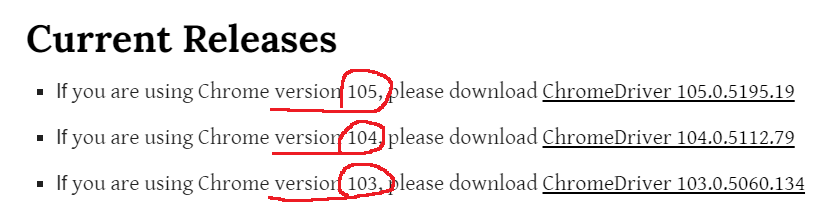
| 잠깐! chromedriver_autoinstaller (패키지 설치 필요) 를 이용하면 자동으로 최신 버전을 다운로드 및 설치 해준다고 합니다 |
import chromedriver_autoinstaller
chromedriver_autoinstaller.install()
소스코드를 적어볼게요.
먼저 필요한 패키지들을 설치했다는 가정 하에 import 를 해옵니다.
selenium 은 이렇게 2개 정도 갖다 쓰면 되구요.
from selenium import webdriver
from selenium.webdriver.common.by import By
browser = webdriver.Chrome()
자동화된 브라우저를 띄워서 페이지에 접속을 해볼게요. url 은 네이버 금융 내 '시가총액' 을 클릭했을 때 나타나는 값으로 하면 됩니다.
# 1. 페이지 이동
url = 'https://finance.naver.com/sise/sise_market_sum.naver?&page='
browser.get(url)
실행해보니 접속이 잘 되네요!
기본적으로 몇 가지 항목이 선택되어 있습니다. 이것들을 없애주기 위해서는 모든 체크 항목을 다 가지고 와서 체크가 되어 있다면 '선택 해제' 를 해주면 돼요. 물론 모든 항목이 아닌 체크되어 있는 항목만 가지고 와도 되지만 몇 개 없기 때문에 저는 전자의 방법을 사용해보겠습니다.
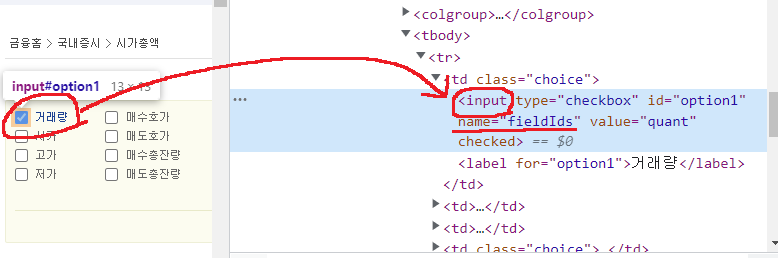
개발자 도구로 html 구조를 보니 name 속성이 fieldIds 인 input 엘리먼트를 가져오면 되겠네요? 코드로 적어봅니다. 이 엘리먼트가 선택이 되었다면 클릭을 통해 체크 해제를 해주는거에요.
# 2. 조회 항목 초기화 (체크되어 있는 항목 체크 해제)
checkboxes = browser.find_elements(By.NAME, 'fieldIds')
for checkbox in checkboxes:
if checkbox.is_selected(): # 체크된 상태라면?
checkbox.click() # 클릭 (체크 해제)
실행시켜보면 이렇게 모든 체크가 싹 사라집니다.

이제는 우리가 원하는 값만 체크를 해줘야겠네요.
앞에서 가져온 엘리먼트들을 재활용하는데, 그전에 먼저 리스트로 우리가 원하는 값을 정의해줍니다.
'거래량, 전일거래량, PER, PRB, 외국인비율'
이것들을 가지고 해볼게요.
items_to_select = ['거래량', '전일거래량', 'PER', 'PBR', '외국인비율']
참고로 PER(배), PBR(배) 와 같은 정보는 개발자 도구 상에서 보면 label 엘리먼트 외부에 (배) 라고 붙어있고 내부에는 PER, PRB 까지만 적혀 있기 때문에 리스트에도 PER, PBR 까지만 적어줍니다. 여기서는 label 엘리먼트의 text 값으로 비교를 할거거든요.

리스트가 정의되었으면 다시 반복문을 통해서 비교를 하는데, html 을 잘 살펴보면 input 이라는 엘리먼트와 형제 관계로 label 엘리먼트가 있습니다. 우리가 알고 있는 건 input 엘리먼트이므로 label 엘리먼트의 text 값을 확인하기 위해서는 보통 부모 엘리먼트인 td 로 이동을 한 다음 td 엘리먼트 내에서 label 을 찾는 식으로 접근합니다.
그래서 이렇게 부모로 갔다가 다시 label 로 내려온 뒤에 text 를 비교하면 아주 깔끔하게 처리가 됩니다.

리스트 항목과 비교하여 일치한다면 체크까지 해줄게요.
for checkbox in checkboxes:
parent = checkbox.find_element(By.XPATH, '..') # 부모 element
label = parent.find_element(By.TAG_NAME, 'label') # label element
# print(label.text) # 이름 확인
if label.text in items_to_select: # 선택 항목과 일치한다면
checkbox.click() # 체크
체크가 다 되었으니 이제 '적용하기' 버튼을 클릭할 차례입니다.
이 버튼은 a 엘리먼트로 되어 있고 href 속성이 javascript:fieldSubmit() 이네요? 이건 name / id 와 같은 식별자가 없기 때문에 html 내에서 주소처럼 사용되는 XPath 를 이용해서 문서 전체 중에서 엘리먼트가 a 이고 href 속성이 무슨무슨 값인 녀석을 찾도록 하면 됩니다.
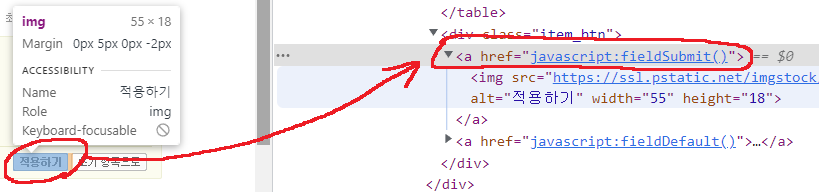
코드는 이렇게 되구요.
# 4. 적용하기 클릭
btn_apply = browser.find_element(By.XPATH, '//a[@href="javascript:fieldSubmit()"]')
btn_apply.click()
클릭도 바로 해줍니다.
잘 따라오고 계시죠?

거의 다 됐습니다.
이제 1페이지, 2페이지를 반복하면서 37페이지까지 보여지는 모든 데이터들을 가져와서 엑셀로 저장하면 됩니다. 이 때 아주 아주 좋은 방법이 있는데요. 바로 pandas 를 이용하는 겁니다.
pandas 에는 read_html() 이라는 게 있는데 이걸 이용하면 일일이 table 을 찾고 그 table 속에 있는 th, tr, td 들을 구분해서 가져올 필요 없이 한 방에 테이블 정보 전체를 싹 가져올 수 있게 돼요.
read_html() 에는 페이지 소스 또는 url 을 넣으면 되는데 우리는 browser.page_souce 를 넣어주도록 하겠습니다.
import pandas as pd
# 5. 데이터 추출
df = pd.read_html(browser.page_source)
그러면 현재 페이지에 총 3개의 table 이 발견되는데요. 각각의 값들을 찍어서 확인한 결과 첫 번째 테이블은 시가총액 부분이고 두 번째 테이블이 코스피 종목들인것 같아요.
그래서 두 번째 테이블(인덱스 1에 해당)로 선택을 하구요.
df = pd.read_html(browser.page_source)[1]
한 가지 문제가 있는데 바로 row 와 column 에 NaN 이라는 결측치가 보이는 겁니다.
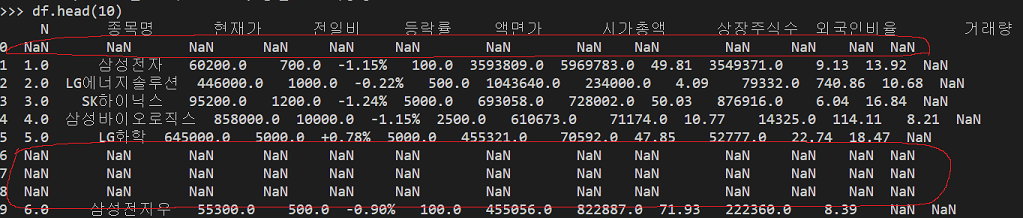
비어 있는 데이터가 왜 있을까 해서 보니까 5개 종목 단위로 이렇게 줄을 긋는 부분이 <tr/> 3개로 구성되어 있기도 하구요. 또 colspan="13" 으로 되어 있어서 실제로 화면에 보여지는 column 은 13개가 아님에도 불구하고 dummy column 이 붙어서 13개로 처리가 되고 있습니다.
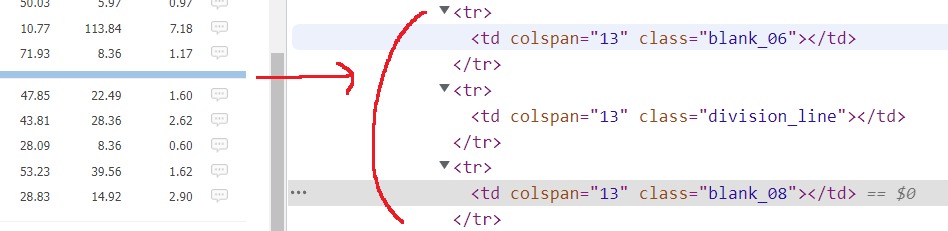
이런 결측치는 다행히 아주 간단하게 없앨 수 있어요.
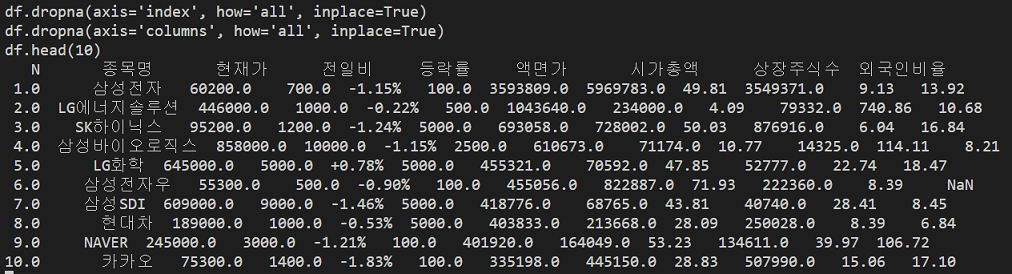
df.dropna(axis='index', how='all', inplace=True)
df.dropna(axis='columns', how='all', inplace=True)
이렇게 하면 row 또는 column 대상으로 '모든 데이터가 NaN 인 경우' 삭제를 해줄 수 있습니다.
head(10) 를 통해 상위 10개 결과를 다시 확인해보면 데이터가 깔끔하게 남네요.
그럼 마지막으로 정제된 데이터를 엑셀로, csv 형태로 저장해주면 되겠습니다.
한 가지 주의할 점은, 데이터를 저장할 때 헤더 부분은 딱 1번만 들어가면 되겠죠?

매번 50개 종목마다 헤더가 들어갈 필요는 없기 때문에 처음으로 파일을 만드는 경우라면 헤더를 넣고 그 이후에는 헤더를 넣지 않도록 파일의 유무를 따져서 처리해주도록 하겠습니다.
코드로는 이렇게 하면 되구요.
# 6. 파일 저장
f_name = 'sise.csv'
if os.path.exists(f_name): # 파일이 있다면? 헤더 제외
df.to_csv(f_name, encoding='utf-8-sig', index=False, mode='a', header=False)
else: # 파일이 없다면? 헤더 포함
df.to_csv(f_name, encoding='utf-8-sig', index=False)
print(f'{idx} 페이지 완료')
마지막으로 반복문을 이용해서 1페이지부터 반복을 하다가 가져올 데이터가 비어있다면 반복문을 탈출해주면 됩니다.
그럼, 실행해볼까요?
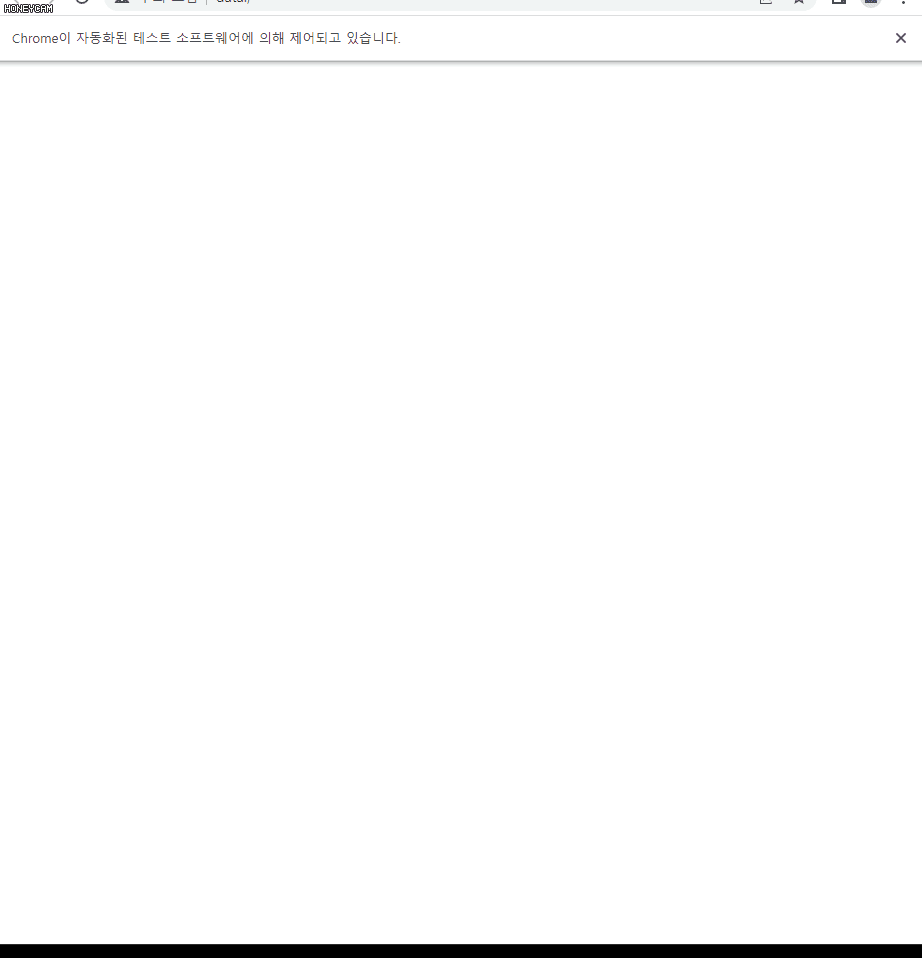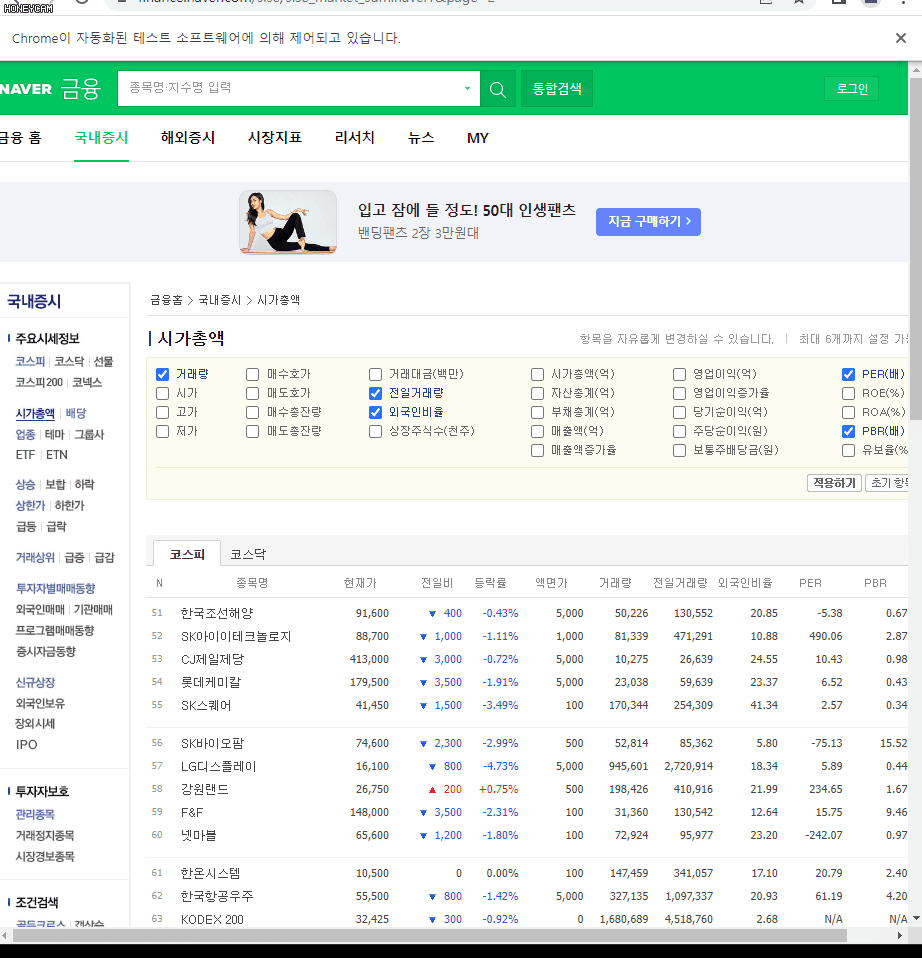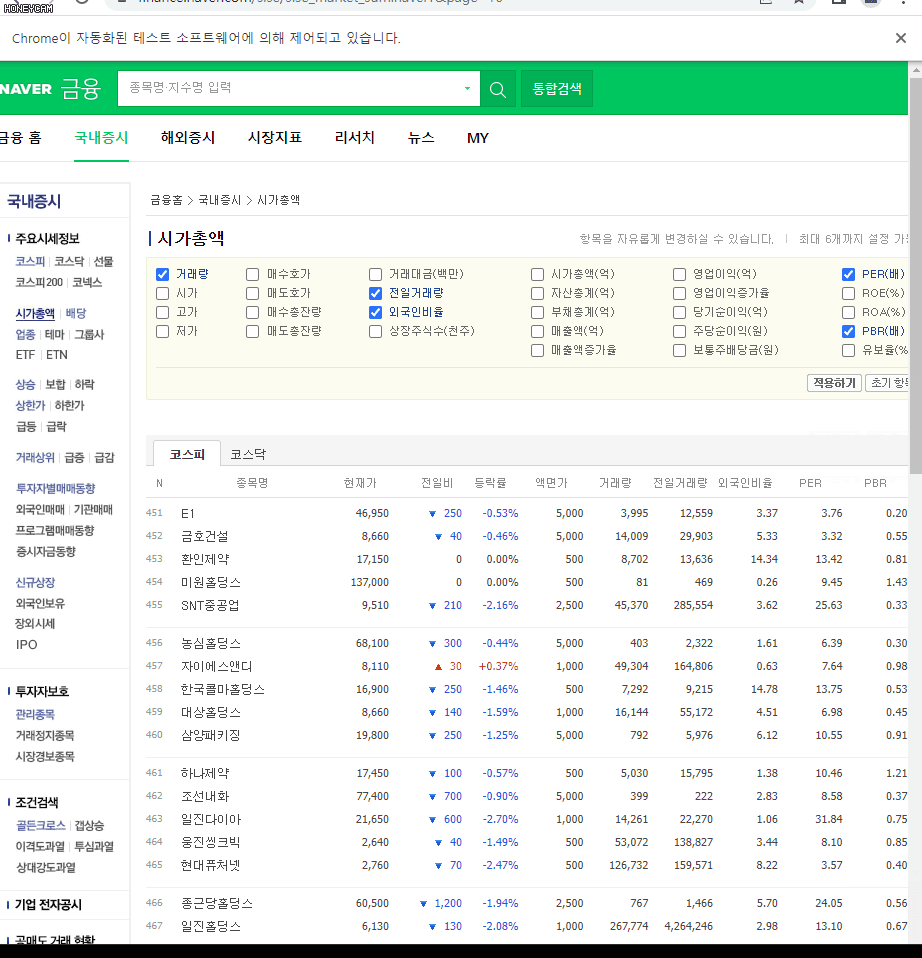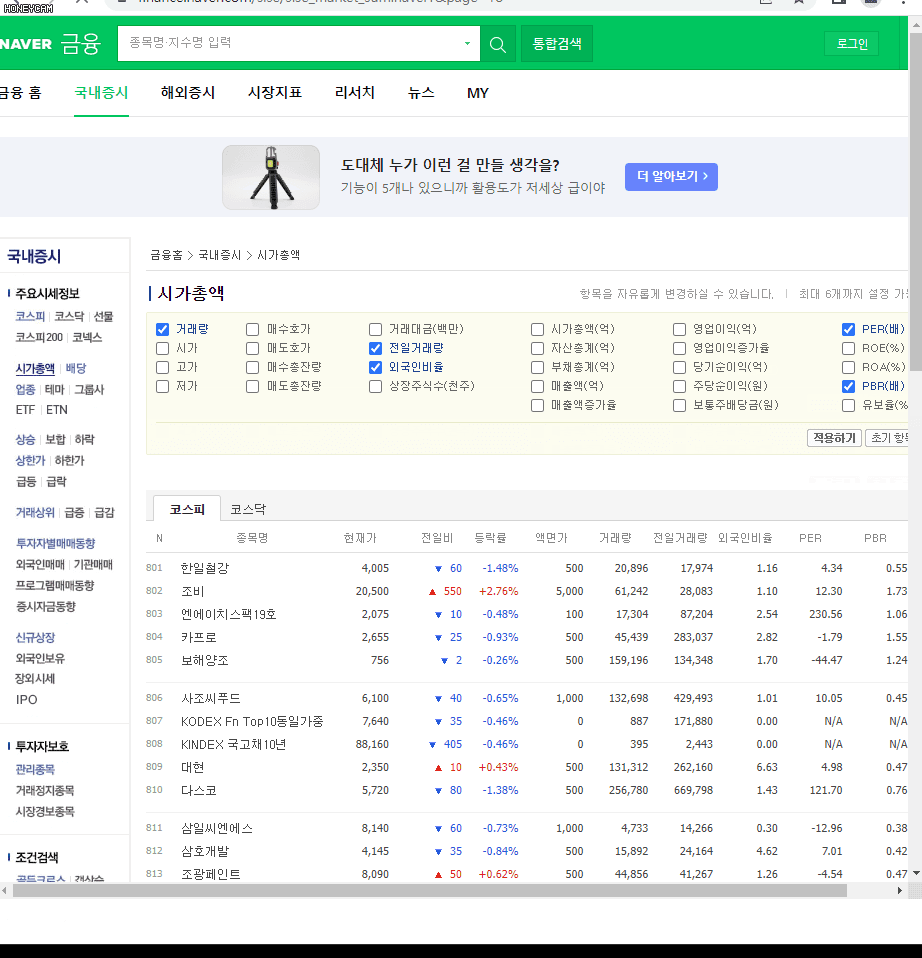
짠... 아주 빠르게 순식간에 원하는 항목을 체크하고 나서 1페이지부터 순회하면서 좌르르르 데이터를 가져오고 있습니다.
결과물을 확인해보면 이렇게 보시는 것처럼 잘 정리가 되어 있네요!
이번에 준비한 강의는 여기까지입니다.
주식 투자 하시는 분들에게 필요한 데이터를 파이썬을 이용해서 쉽고 빠르게 깔끔한 형태로 가져오는 내용을 공부해봤구요. 이제는 여러분들의 입맛에 맞게 리스트만 바꿔서 필요할 때마다 실행 버튼만 딸깍 눌러주면 몇 초만에 주식 정보를 가져올 수 있게 되었습니다.
글보다는 영상이 편하신 분들은 아래를 참고해주세요 ^^
파이썬 공부하시는 분들께 도움되길 바라며, 이만 줄이겠습니다 😄
읽어주셔서 감사합니다.
전체 소스 코드
import os
import pandas as pd
from selenium import webdriver
from selenium.webdriver.common.by import By
browser = webdriver.Chrome()
browser.maximize_window() # 창 최대화
# 1. 페이지 이동
url = 'https://finance.naver.com/sise/sise_market_sum.naver?&page='
browser.get(url)
# 2. 조회 항목 초기화 (체크되어 있는 항목 체크 해제)
checkboxes = browser.find_elements(By.NAME, 'fieldIds')
for checkbox in checkboxes:
if checkbox.is_selected(): # 체크된 상태라면?
checkbox.click() # 클릭 (체크 해제)
# 3. 조회 항목 설정 (원하는 항목)
items_to_select = ['거래량', '전일거래량', 'PER', 'PBR', '외국인비율']
for checkbox in checkboxes:
parent = checkbox.find_element(By.XPATH, '..') # 부모 element
label = parent.find_element(By.TAG_NAME, 'label')
# print(label.text) # 이름 확인
if label.text in items_to_select: # 선택 항목과 일치한다면
checkbox.click() # 체크
# 4. 적용하기 클릭
btn_apply = browser.find_element(By.XPATH, '//a[@href="javascript:fieldSubmit()"]')
btn_apply.click()
for idx in range(1, 40): # 1 이상 40 미만 페이지 반복
# 사전 작업 : 페이지 이동
browser.get(url + str(idx)) # http://naver.com....&page=2
# 5. 데이터 추출
df = pd.read_html(browser.page_source)[1]
df.dropna(axis='index', how='all', inplace=True)
df.dropna(axis='columns', how='all', inplace=True)
if len(df) == 0: # 더 이상 가져올 데이터가 없으면?
break
# 6. 파일 저장
f_name = 'sise.csv'
if os.path.exists(f_name): # 파일이 있다면? 헤더 제외
df.to_csv(f_name, encoding='utf-8-sig', index=False, mode='a', header=False)
else: # 파일이 없다면? 헤더 포함
df.to_csv(f_name, encoding='utf-8-sig', index=False)
print(f'{idx} 페이지 완료')
browser.quit() # 브라우저 종료주의사항
웹에서 데이터를 긁어오는 작업은 경우에 따라 대상 서버에 부하를 주게 될 수도 있습니다. 그러면 서버에서는 감지를 통해 해당 IP 를 차단하는 등의 제재를 가할 수도 있고, 심한 경우 법적 분쟁이 발생할 수도 있어요(데이터의 무단 사용 등). 그러므로 가급적 이 글에서 알려드린 범위 내에서 학습 용도로만 가볍게 사용하시길 권해드립니다.
'파이썬 강의 > 실전 프로젝트' 카테고리의 다른 글
| [파이썬] 틀린그림찾기 자동으로 하기 (2) | 2022.08.24 |
|---|---|
| [파이썬] 퍼즐 보블 (Puzzle Bobble) 게임 개발 (14) | 2021.08.31 |
| [파이썬] 황금캐기 게임 개발 (2) | 2021.06.01 |
| [파이썬] 기억력 테스트 게임 개발 (4) | 2021.04.16 |
- Total
- Today
- Yesterday
- vscode
- 파이썬
- Coding
- Tkinter
- game
- 행맨
- 비주얼 스튜디오 코드
- pygame
- nanobanana
- repl.it
- 파이게임
- c언어
- 환경설정
- pycharm
- ChatGPT
- 나도코딩
- 아나콘다
- Visual Studio Code
- 주피터노트북
- Unity
- 프롬프트 엔지니어링
- 코랩
- onlineclass
- Xcode
- Mac
- coloso
- 챗GPT
- Colab
- GUI
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |